
Lead developer of SiriDB.


How we store time series in SiriDB
SiriDB is an open source time series database with cluster support for scaling and redundancy. The source code and documentation on how to install SiriDB can be found on GitHub.
What do time series in SiriDB look like?
Time series in SiriDB are uniquely identified by name and can have any number of points. A single point consists of a timestamp and value. SiriDB allows you to insert points in any order. That way it is possible to backfill the database with old data while new values are coming in as well.
SiriDB supports time series for numeric data types (integer or float). You do not need to specify the type in advance. When inserting data into SiriDB, new time series will be created automatically for the correct data type.
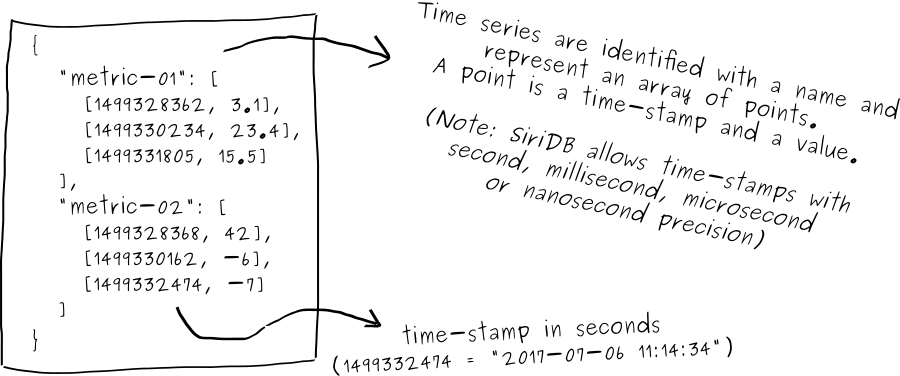
Time series can be queried by name, regular expressions or dynamic groups. In this blog I will not explain how to select time series, but the SiriDB documentation contains a section that explains more about this subject:
https://docs.siridb.com/series/list_series/
Scaling and redundancy
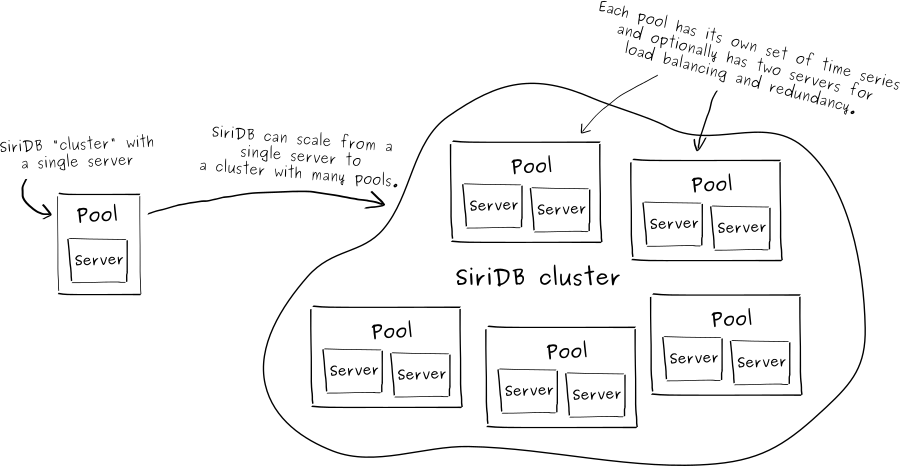
SiriDB can distribute time series across multiple pools and for redundancy each pool can have two servers. If one server in a pool fails, the other server will still be able to handle all requests so the database can still be used. This is also helpful in case you want to install a new version of SiriDB. By upgrading one server in each pool at the time, upgrading can be done without any downtime.
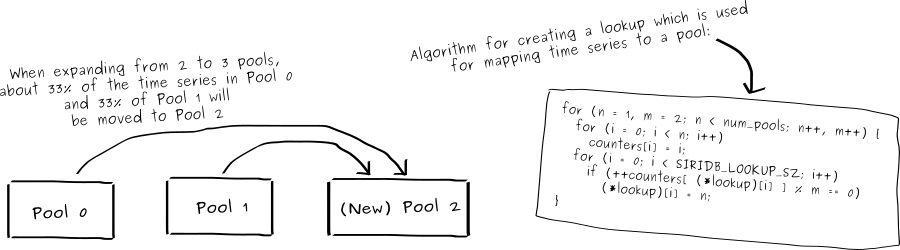
Instead of a global index for the time series, SiriDB uses a custom crafted algorithm to map time series to a pool. This algorithm is designed in such a way that, when adding a new pool, data is only moved from existing pools to the new pool and not between existing pools. During the process of extending a database with a new pool, a copy of the old lookup is kept to make sure queries and inserts keep working. SiriDB intentionally runs the expansion with low priority in the background so the database remains fully operational when a new pool is being added. The same is true for adding a second server to a pool. SiriDB will replicate all data to the new server in the background and the new server becomes a full cluster member as soon as the initial replication is finished.
Insert data into SiriDB
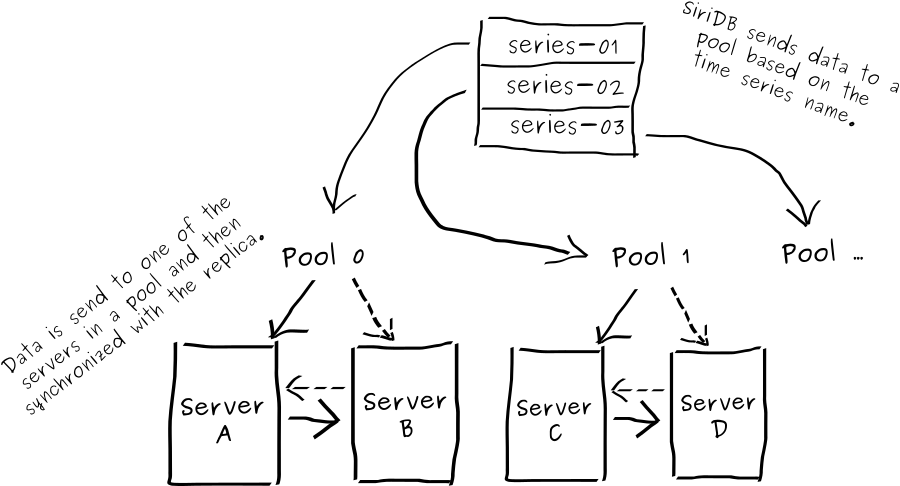
When new data is received by SiriDB, it first determines in which pool the data should be stored, after which the data is sent to the specific pool. In case a pool has two servers, one is randomly chosen and this server will be responsible for updating the replica by using a fifo buffer on disk.
Now let’s look at how the data is stored on a single server. A server receives data and stores this in a buffer. The buffer is immediately saved on disk and is also kept in memory. The buffer can store a fixed number of points for each time series. This number depends on the buffer size which can be configured when creating a database. Since SiriDB does not read from the buffer-file it does not care about the order of how the points are saved. In memory the points are saved in order so queries can return the points from the buffer very fast.
Tip: By placing the buffer file on fast storage like an SSD, the ingestion throughput of SiriDB can be improved while still using cheap traditional storage for all the shards data. The location for the buffer file can be set in the database configuration file (dbpath/database.conf).
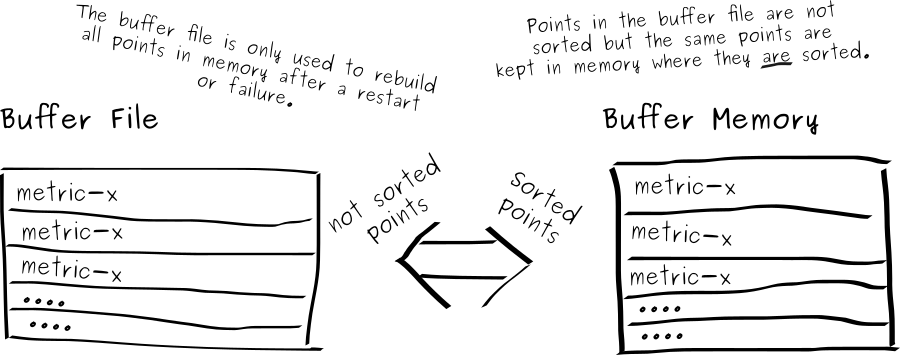
When the buffer for a time series is “full” and new points can’t be saved, then both the new, and the buffer data will be sent to shards. Shards are files for specific time-ranges. On the initial setup of a SiriDB database the shard duration must be chosen.
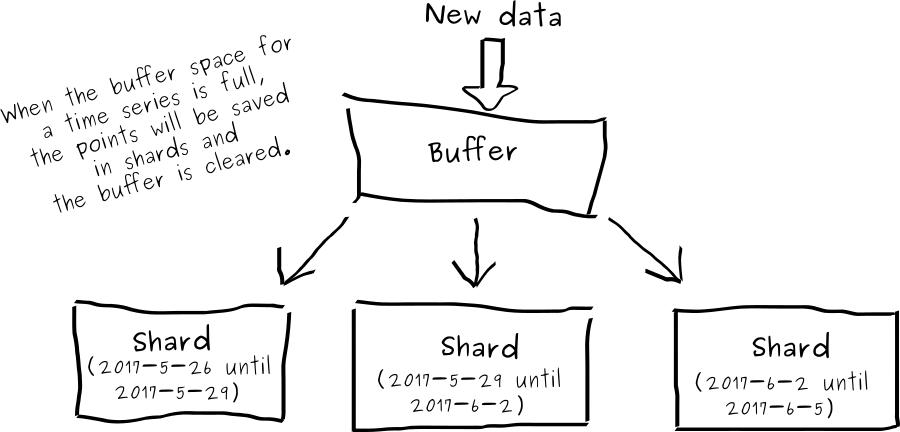
A single shard has chunks of ordered points, each with an index. This index consists of a time series identifier, a start time, end time and the number of points in the chunk. All points in a chunk belong to the time-range of the specific shard so chunks between shards can never have an overlap in time. Within one shard, time series can have multiple chunks which may overlap in time. If this is the case then both the time series and the shard are marked to have an overlap. When selecting data, SiriDB usually just takes the chunks in the right order but when an overlap is detected, SiriDB will also sort the points where required.

Since sorting in general is a slow process which might slow down SiriDB queries, we ideally do not want overlaps. We also do not want a lot of chunks with only a few points since each chunk requires memory and a little disk space. Query time would improve if we could reduce the chunks into larger ones. To solve this SiriDB has a thread running for optimizing shards. This task periodically checks for shards which can be optimized. It then takes all chunks for a time series within this shard and re-writes the chunks so that no overlap exists and each chunk has an optimal amount of points.
When SiriDB is started, it needs to rebuild an index for all chunks inside the shards. Without separate index files this is a slow process since SiriDB needs to read through the whole shard to find the indexes for all chunks. This could be solved by writing indexes to separate files while sharding but this would require almost twice as much file handlers and also slows down writing to shards although the difference is not that much.
This is the reason SiriDB uses another solution, and that is by using the optimization task to build index files for shards. Only while optimizing, the index and points are written in separate files. This process stops when new data is written to the shard, no matter if the optimization task is still running or not.
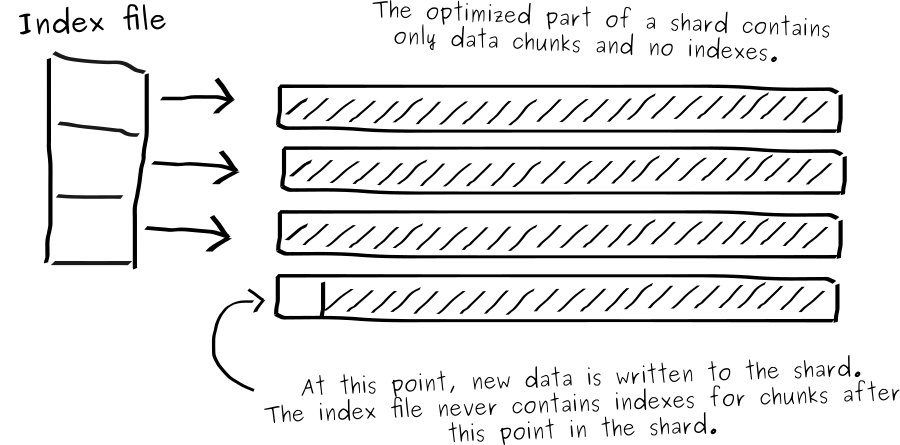
Once optimization is finished, SiriDB can use the index file at startup which obviously is a lot faster compared to reading through the whole shard.
Select data from SiriDB
Now we know how SiriDB stores time series data, let’s look at what happens when we perform a query.
The SiriDB server which receives a query forwards the query to the correct pool(s) if required. In case a pool has two available servers, one is chosen randomly.
Note: If the time series is indeed in another pool, the server does not yet know whether or not the time series actually exists. The server only knows that if the time series does exist, in which pool it should be.
Next, the server in the pool determines which chunks are required to answer the query and loads them from the shards. Finally, it checks if the buffer contains points which are applicable to the requested time-range and adds them as well. The points will then be sent to the server which received the original request. That server in turn sends the final result to the client.
SiriDB supports aggregation and filter methods which can save much network traffic to the client. When possible the aggregation and filter methods are performed immediately after reading the time series data in a pool. This way less data needs to be sent back to the server responsible for handling the query. This also spreads the CPU load for the aggregation across multiple pools.
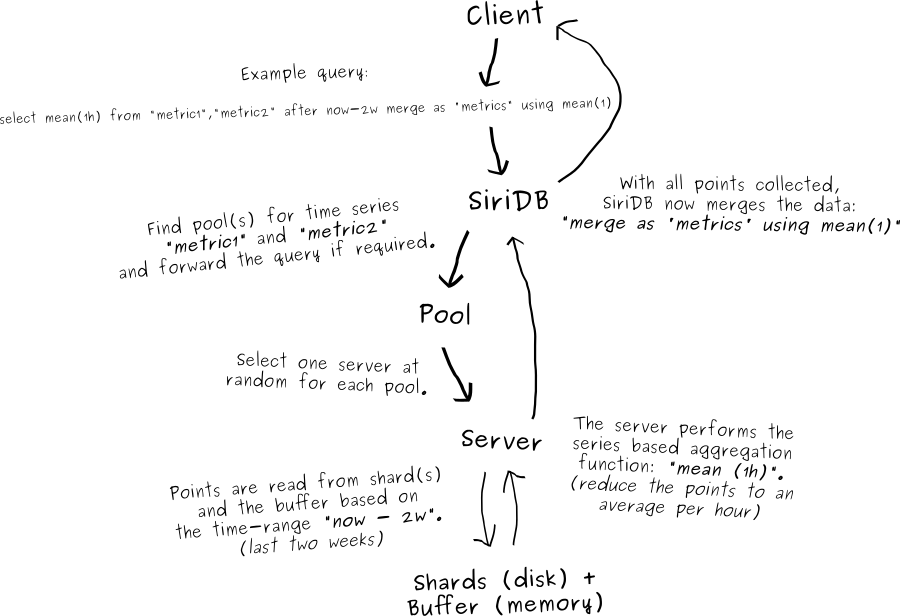
For simplicity I left out details about how the full process works but I hope it briefly explains how SiriDB works with time series data!